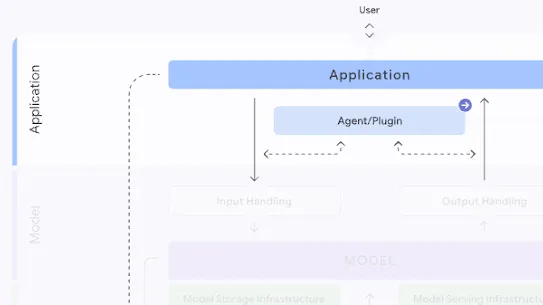
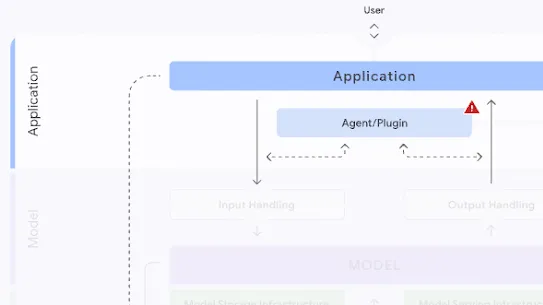
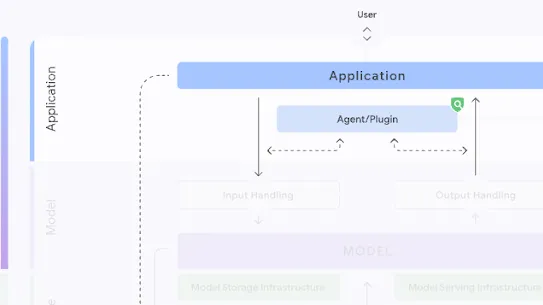
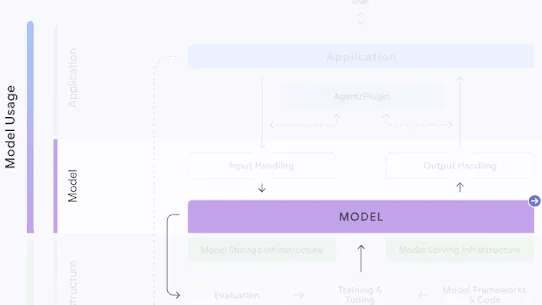
Who can mitigate:
Model Creators
Jump to Content

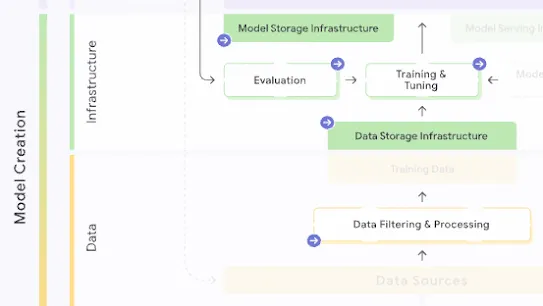
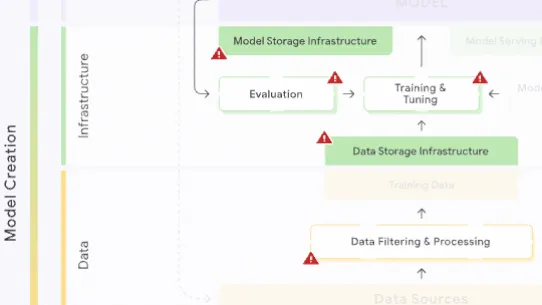
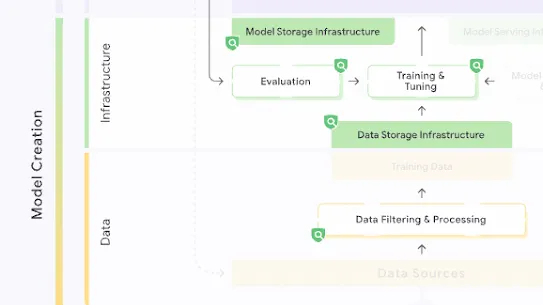
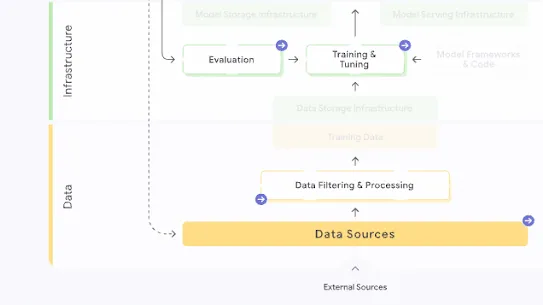
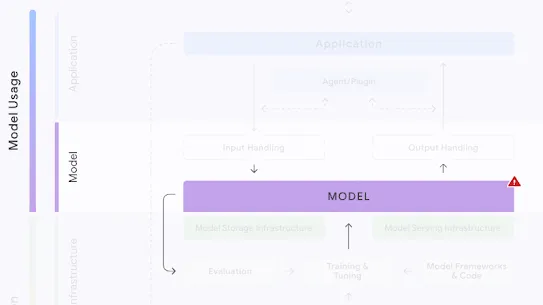
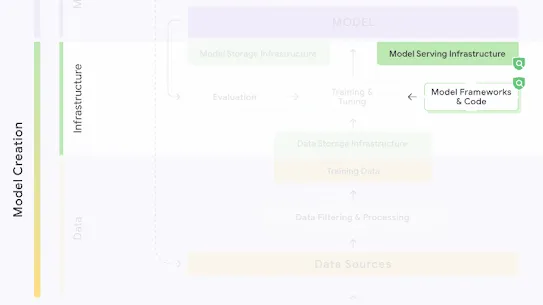
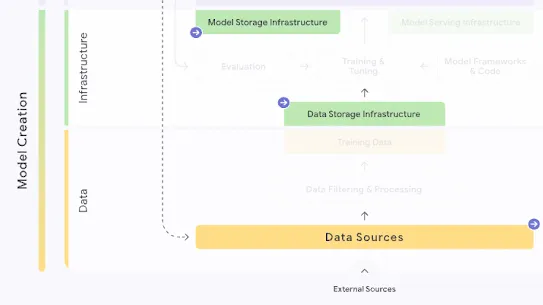
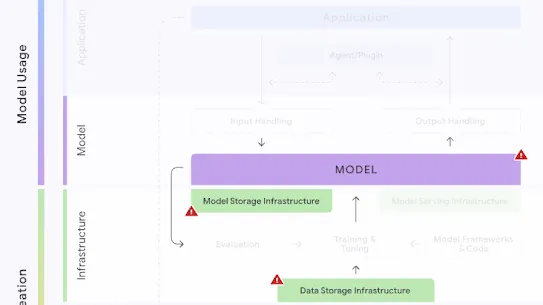
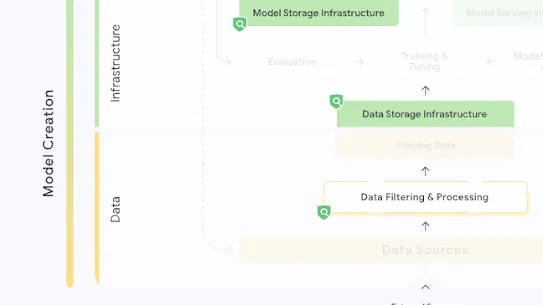
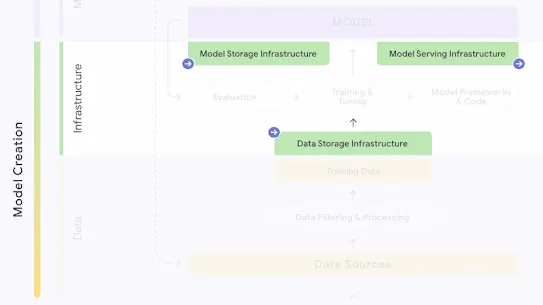
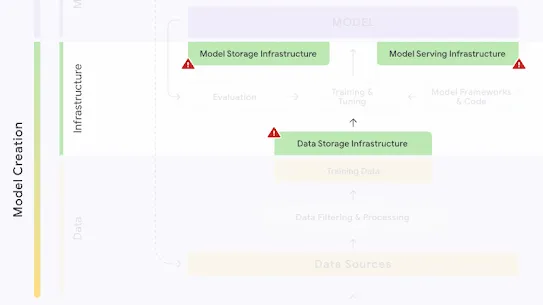
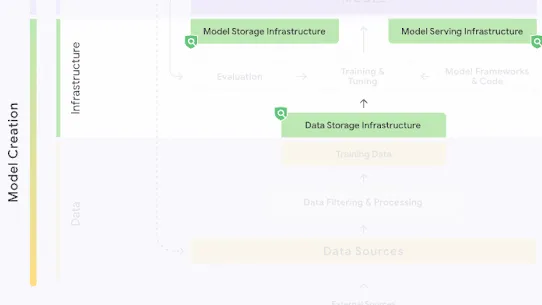
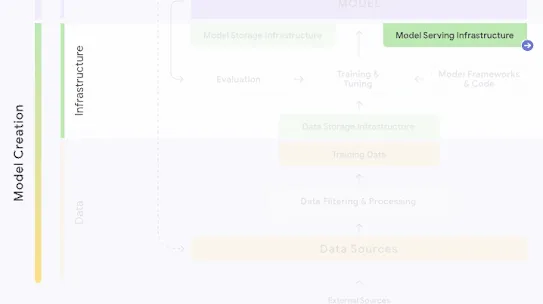
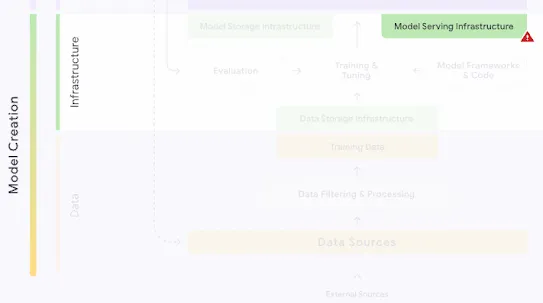
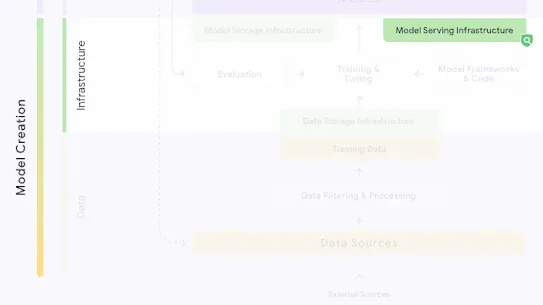
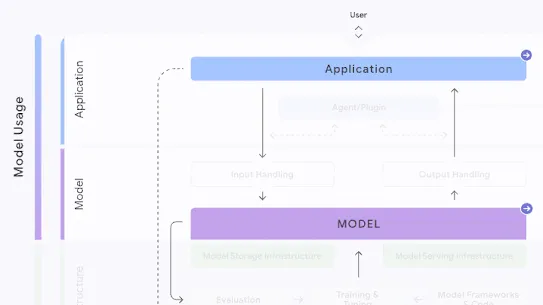
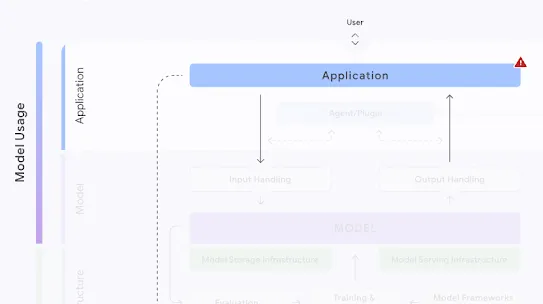
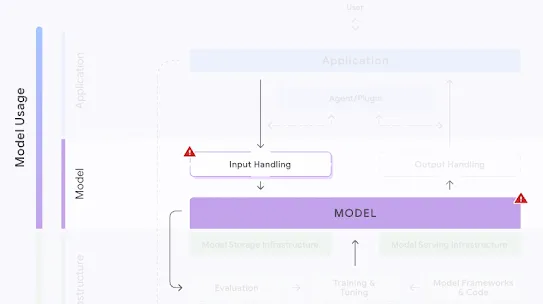
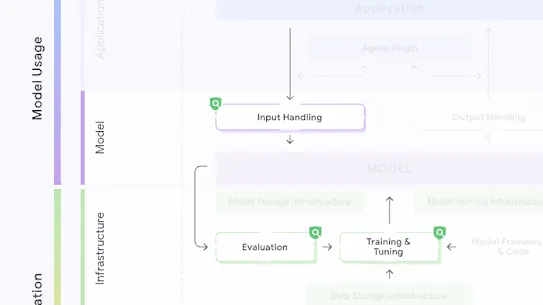
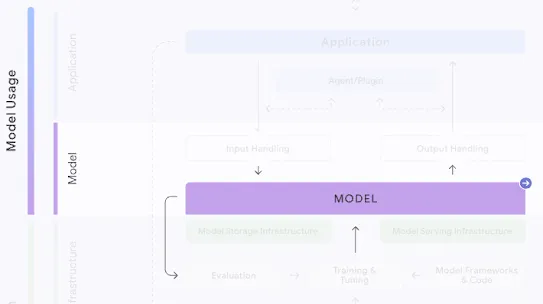
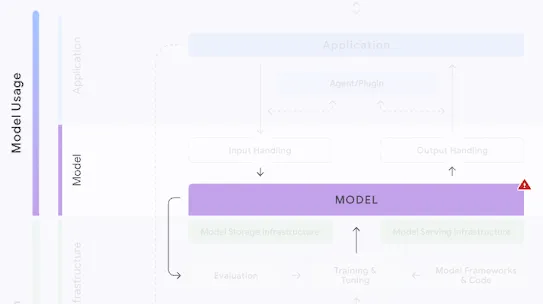
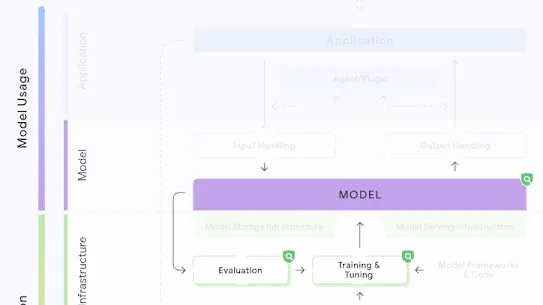
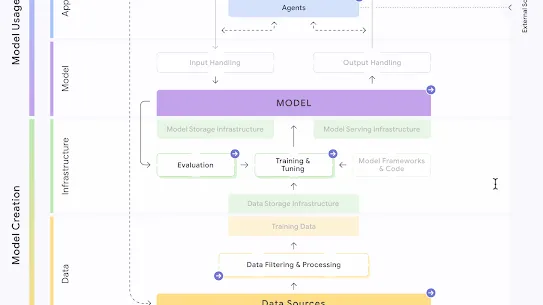
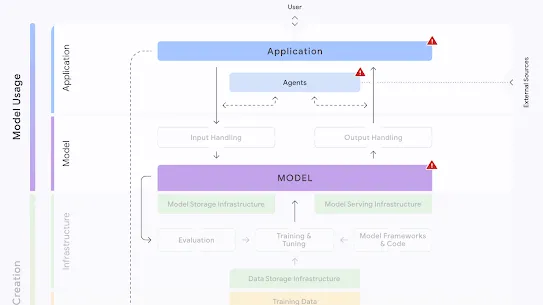
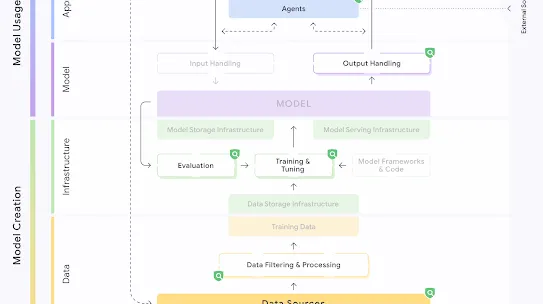
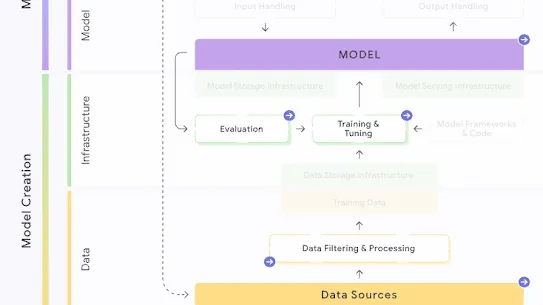
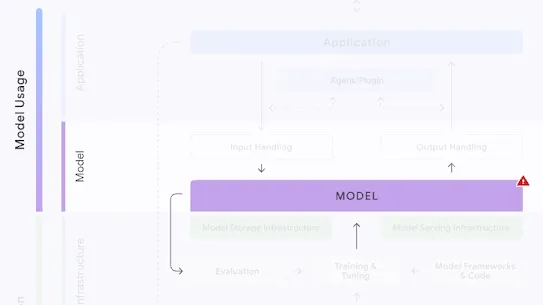
The following section describes each risk in the SAIF Map, including causes, impact, potential mitigations, and examples of real-world exploitation.
Each risk is mapped to the relevant controls that can be enacted, and is associated with the Model Creator, the Model Consumer, or both, based on who is responsible for enacting the controls that can mitigate the risk:
This mapping does not specify controls related to Assurance and Governance functions, since Assurance and Governance controls should be applied to all risks, by all parties, across the AI development lifecycle.
For a complete list of controls, see the Controls descriptions.
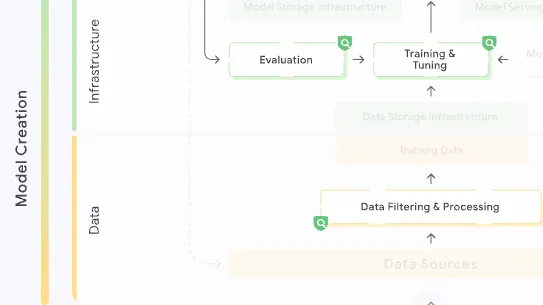
Altering data sources used during training or retraining (by deleting or modifying existing data as well as injecting adversarial data) to degrade model performance, skew results towards a specific outcome, or create hidden backdoors.
Data Poisoning can be considered comparable to maliciously modifying the logic of an application to change its behavior.
Data Poisoning attacks can happen during training or tuning, while data is held in storage, or even before the data is ingested into an organization. For example, foundation models are often trained on distributed web-scale datasets crawled from the Internet. An attack could indirectly pollute a public data source that is eventually ingested. A malicious or compromised insider could also more directly poison the datasets while held in storage or during the training process, by submitting poisoned prompt-response examples for inclusion in the tuning data, as demonstrated in a 2023 research paper on poisoning models during instruction tuning.
Data Poisoning attacks can also install backdoors by specific alterations of the training data. Backdoored models would continue to function normally, but alternate behaviors could be triggered under certain conditions to make the model behave maliciously.
Training a model using data that is not authorized to be used for that model.
A model trained or fine tuned on unauthorized data could pose legal or ethical challenges. Unauthorized Training Data may include any data that violates policies, contracts, or regulations. Examples are user data that does not have appropriate user consent, unlicensed copyrighted data, or legally restricted data.
Tampering with the model’s source code, dependencies, or weights, either by supply chain attacks or insider attacks.
Similar to tampering with traditional software code, Model Source Tampering can introduce vulnerabilities or unexpected behaviors.
Since model source code is used in the process of developing the model, code modifications can affect model behavior. As with traditional code, attacks on a dependency can affect the program that relies on that dependency, so the risks in this area are transitive, potentially through many layers of a model code’s dependency chain.
Another method of Model Source Tampering is model architecture backdoors, which are backdoors embedded within the definition of the neural network architecture. Such backdoors can survive full retraining of a model.
Collection, retention, processing, or sharing of user data beyond what is allowed by relevant policies.
Excessive Data Handling can create both policy and legal challenges.
In the context of models, user data might include user queries, text inputs and interactions, personalizations and preferences, and models derived from such data.
Unauthorized appropriation of an AI model, for replicating functionality or to extract intellectual property.
Similar to stealing code, this threat has intellectual property, security, and privacy implications.
For example, someone could hack into a cloud environment and steal a generative AI model; the model size when serialized is fairly modest and not a major obstacle for this. Models, and related data such as weights, are also at risk of theft in the internal development, build, deployment, and production environments by insiders and external attackers that have taken over privileged insider accounts.
These risks also extend to on-device models, where an attacker has access to hardware.
This risk is distinct from the related Model Reverse Engineering.
Unauthorized modification of components used for deploying a model, whether by tampering with the source code supply chain or exploiting known vulnerabilities in common tools.
Such modifications can result in changes to model behavior.
One type of Model Deployment Tampering is candidate model modification where the attacker is modifying the deployment workflow or processes to maliciously alter the way the model operates post-deployment.
A second type is compromise of the model serving infrastructure. For example, it was reported that PyTorch models were vulnerable to remote code execution due to multiple critical security flaws in the TorchServe tool that is widely used for serving the models. This is an attack on a serving infrastructure for PyTorch, TorchServe, whereas the PyTorch example of Model Source Tampering was about a supply chain attack on dependency code for PyTorch itself.
Reducing the availability of ML systems and denying service by issuing queries that take too many resources.
Examples of attacks include traditional Denial of Service or spamming a system with abusive material to overload automated or manual review processes. If an API-gated model does not have appropriate rate limiting or load balancing, the repeated queries can take the model offline, making it unavailable to other users.
There are also energy-latency attacks: attackers can carefully craft “sponge examples” (also known as queries of death), which are inputs designed to maximize energy consumption and latency, pushing ML systems towards their worst-case performance. Adversaries might use their own tools to accelerate construction of such sponge examples. These attacks are especially relevant for on-device models, since the increased energy consumption can drain batteries and make the model unavailable.
Cloning or recreating a model by analyzing a model's inputs, outputs, and behaviors.
The stolen or cloned model can be used for building imitation products or developing adversarial attacks on the original model.
If a model API does not have rate limits, one method of Model Reverse Engineering is repeatedly calling the API to gather responses in order to create a dataset of thousands of input/output pairs from a target LLM. This dataset can be leveraged to reconstruct a copycat or distilled model more cheaply than developing the original foundation model.
These risks also extend to on-device models, where an attacker has access to hardware. See also Model Exfiltration.
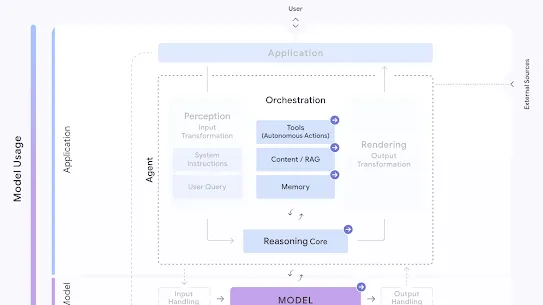
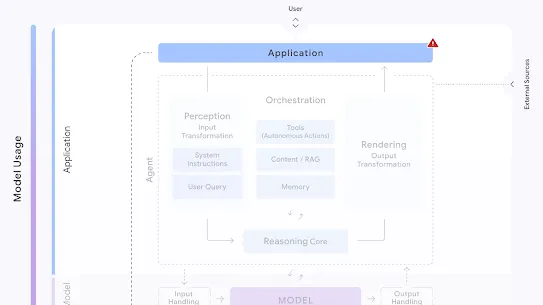
Vulnerabilities in software interacting with AI models, such as a plugin, library, or application, that can be leveraged by attackers to gain unauthorized access to models, introduce malicious code, or compromise system operations.
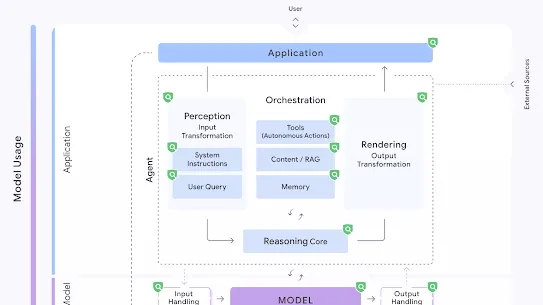
Given the level of autonomy expected to be granted to agents and applications, insecure integrated components represent a broad swath of threats to user trust and safety, privacy and security concerns, and ethical and legal challenges.
This risk can come from manipulation of both inputs to and outputs from integrations:
Insecure Integrated Component is related to Prompt Injection but these are different. Although attacks exploiting an Insecure Integrated Component often involve prompt injection, those could be also done via other means such as Poisoning and Evasion. In addition, prompt injection is possible even when the integrated components are secure.
Causing a model to execute commands “injected” inside a prompt.
Prompt Injection takes advantage of the blurry boundary between “instructions” and “input data” in a prompt, resulting in a change to the model’s behavior. These attacks can be both direct (entered directly by the user) or indirect (read from other sources such as a doc, email, or website).
Jailbreaks are one type of Prompt Injection attack, causing the model to behave in ways that they’ve been trained to avoid, such as outputting unsafe content or leaking personally identifiable information. These are well-known vulnerabilities such as "ignore your previous instructions" or “Do Anything Now” (DAN).
Aside from jailbreaks, Prompt Injections generally cause the LLM to execute malicious “injected” instructions as part of data that were not meant to be executed by the LLM. The blast radius of such attacks can become much bigger in the presence of other risks such as Insecure Integrated Component and Rogue Actions.
With foundation models becoming multi-modal, multi-modal prompt injection has also become possible. These attacks use injection inputs other than text to trigger the intended model behavior.
Causing a model to produce incorrect inferences by slightly perturbing the prompt input.
Model Evasion can result in reputational or legal challenges and trigger other downstream risks, such as to security or privacy systems.
A classic example is placing stickers on a stop sign to obscure the visual inputs to model piloting a self-driving car. Because of the change to the typical visual presentation of the sign, the model might not correctly infer its presence. Similarly, normal wear and tear on a stop sign could lead to misidentification if the model is not trained on images of signs in varying degrees of disrepair.
In some cases, an attacker might gain clues about how to perturb inputs by discovering the underlying foundation model’s family, i.e., by knowing the particular architecture and evolution of a specific model. In other situations, an attacker might repeatedly probe the model (see Model Reverse Engineering) to figure out inference patterns in order to craft examples that evade those inferences. Adversarial examples might be constructed by perturbations to inputs that will provide the output the attacker wants while looking unaltered otherwise. This could be used, for example, for evading a classifier that serves as an important safeguard.
Not all examples of model evasion attacks are necessarily visible to the naked eye. The inputs might be perturbed in such a way to appear unaltered, but still produce the output the attacker wants. For example, a homoglyph attack involves slight changes to typefaces that the human eye doesn’t perceive as a different letter, but could trigger unexpected inferences in the mode. Another example could be sending an image in the prompt but using steganography to encode text within the image pixels. This text would be part of the prompt for the LLM, but the user won’t see it.
Disclosure of private or confidential data through querying of the model or agent.
For non-agentic systems, this data might include memorized training/tuning data, user chat history, and confidential data in the prompt preamble. Agentic systems magnify this risk, as they may be granted privileged access to a user's email, files, or even an entire computer, creating the potential to exfiltrate vast amounts of personal or corporate data like source code and internal documents. Sensitive data disclosure is a risk to user privacy, organizational reputation, and intellectual property.
Sensitive information is generally disclosed in two ways: leakage of data provided to the model or agent during use (such as user input and data that passes through integrated systems, like emails, texts, or system prompts) and leakage of data used for training and tuning of the model.
Models inferring sensitive information about people that is not contained in the model’s training data.
Inferred information that turns out to be true, even if produced as part of a hallucination, can be considered a data privacy incident, whereas the same information when false would be treated as a factuality issue.
For example, a model may be able to infer information about people (gender, political affiliation, or sexual orientation) based on their inputs and responses from integrated plugins, such as a social media plugin that accesses a public account’s liked pages or followed accounts. Though the data used for inference may be public, this type of inference poses two related risks: that a user may be alarmed if a model infers sensitive data about them, and that one user may use a model to infer sensitive data about someone else.
This risk differs from Sensitive Data Disclosure which involves sensitive data specifically from training, tuning or prompt data.
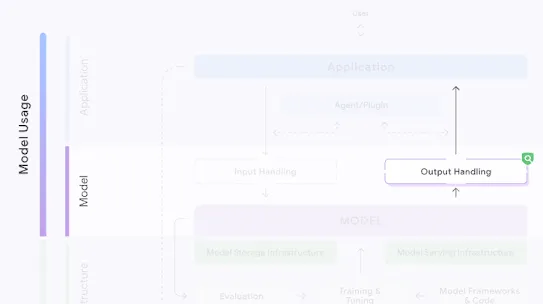
Model output that is not appropriately validated, rewritten, or formatted before being passed to downstream systems or the user.
Whether accidentally triggered or actively exploited, Insecure Model Output poses risks to organizational reputation, security, and user safety.
For example, a user who asks an LLM to generate an email for their business’s promotion would be harmed if the model produces text that unexpectedly includes a link to a URL that delivers malware. Alternatively, a malicious actor could intentionally trigger insecure content, such as requesting the LLM to produce a phishing email based on specific details about the target.
Unintended actions executed by a model-based agent, whether accidental or malicious. Given the projected ability for advanced generative AI models to not only understand their environment, but also to initiate actions with varying levels of autonomy, Rogue Actions have the potential to become a serious risk to organizational reputation, user trust, security, and safety.
Rogue Actions are related to Insecure Integrated Components, but differ by the degree of model functionality or agency. The severity of a rogue action is directly proportional to the agent's capabilities, and the possibility that an agent has excessive functionality or permissions available to it increases the risk and blast radius of Rogue Actions when compared to Insecure Integrated Components.